Clockwork Empires relies internally on a series of tags, as I think we’ve discussed on this blog far too many times. When you go to look for something like food, we check the game for every object with the “raw_food” tag, and then you go to eat it. Here is where the bad news happens: once you have a sufficiently long game, you can stockpile large quantities of food. Let us say that a player has 500 pieces of raw food. Let us also say you have 150 characters – so, to put it into perspective, the player has accumulated 3 days worth of food. (This isn’t even that large a number.) Every day, the 150 characters must go and eat 150 pieces of food out of the 500. The problem is – they want to eat the *closest* food. So now we have to check 500 pieces of food vs 150 players to see which piece is the closest, for a total of 150 * 500 = 75,000 distance queries. Well, that can be a bit slow, especially when our AI budget is very tight and we have a lot to do. However, we’re now seeing games where characters have huge amounts of food – 5,000 pieces of food, say – and the game slows to a crawl. Clearly, smarter programming is required.
A lovely sea-side desert colony sent in by a player as part of a bug report.
Clockwork Empires stores all information about object positions in a spatial dictionary. The handling of tags is done by a “tag index” class, which is essentially a giant array of information consisting of the following attributes: “position, object, previous item with this tag, next item with this tag”. When a tag is set, we grab a tag index from a giant statically allocated pool of tag indices, so that we don’t have a memory allocation, and attach it to the linked list of tags. The problem is… there’s no way to easily find the “closest” tag to your point. What is needed is a spatial acceleration structure of some kind – a way of dividing the world into regions so that we can start in our region, check it for the closest whatever, and then move on.
The solution I came up with after some hacking is very similar to what we already do for raycasting to pick items for selection in-game: an object grid. The world map (256×256) is divided into cells (currently 16×16), and we keep a list of what tags are in each cell as part of the same tag index. A tag can only be in one cell by definition, so we can use the same data structure and make the cell logic part of the existing tag registration/deregistration process. When doing a distance query, we check our cell first for tags – and then we find the closest one in that cell, and we’re good, right? Wrong. You can have this behaviour:
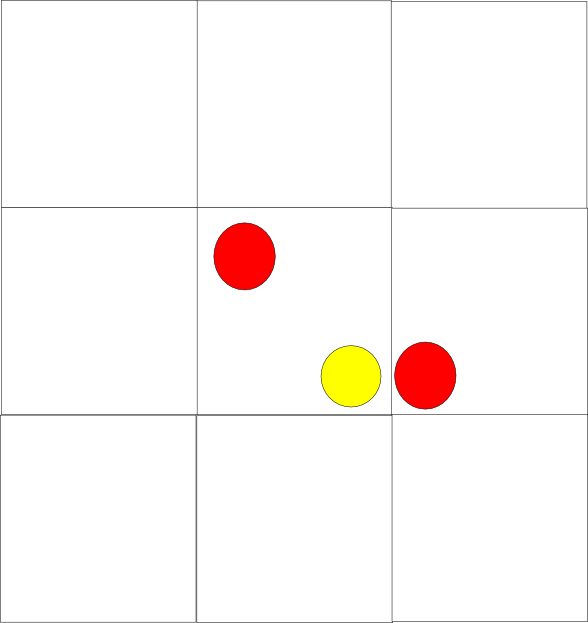
In this lovingly rendered piece of programmer art, the yellow sphere is the player, and the red spheres are two food items. You can have a case where the closest object is in a neighbouring cell, which means we need to find it. So the obvious solution is to check the neighbouring cells. The problem is now that you need some sort of way to stop the algorithm – when do you decide not to check a neighbouring cell? Well, you shouldn’t check a neighbouring cell if you *know* that it’s going to be further away than your most recently seen best object – a problem which is equivalent to asking “what is the closest point in the cell to the current location”? We need to find this quickly, which… well, that seems like math.
Fortunately, cells are axis-aligned bounding boxes. Here is some more hastily drawn programmer art:

We can see that the area around a cell is divided into eight sub-regions. In the upper left subregion, any point up here is closest to the top left corner of the cell. In the upper right subregion, any point is closest to the top right corner of the cell, et cetera. So all we need to do to find the closest point on an axis-aligned bounding box to a given point is to check, for each of the x and y components, whether it is to the left of, to the right of, or in the space defined by the axis-aligned bounding box; this means that we can find the closest point in a neighbouring cell with something like four if statements. We then only check those cells that *might* have an object closer to the player than our current cells, and everything else is a recursive algorithm.
This is a pretty good example of a good technical interview question for an entry level AI programmer, now that I think about it. Anyhow, people should be able to have better performance on larger colonies now.
“We are pleased also very hungry.”
Can items exist in a quad-tree like structure with an id that matches to their list of tags in a hashmap? I guess I have no idea what your code structure is like.
Ok, so I suspected it was something like tons of items around causing the slowdowns (it was also the colonists-finding-colonists that did it).
Good job 🙂
But what happens when all 150 colonists decide they want to eat the same fungal pie, path to it, then find some fishperson has STOLEN THEIR PIE? (Or that another colonist was slightly faster than they were…)
Next blog post:
“Fixed colony riots over multiple attempts to claim items”
I absolutely adore programmer art.
It seems like this solution only helps for cases when the objects are located in different grid squares. Am I correct in thinking that if all my hundreds of food items are stockpiled in one place, the AI will still chug as it processes 75000 calls?
I’m still thinking a bit about how to fix this one.
I have a suggestion:
For every item type in the game (food, weapon, etc), keep a list of cells and a count of how many of that particular type of item is there. Every time a food item is dropped, increment the count of food for that cell or add a new cell to the list if it isn’t there. When a food item decays or is picked up, decrement the count for that cell and if the count is 0 remove the cell entirely from the list. Now when looking for food items you only have to iterate through the cells on the food list instead of all the cells in the game.
So a stack of is in fact 500 items in one place, and not a special item with a tag of “N=500” on it?
Wait, i thought you have tags at cells too. If no, why wouldn’t you make that cells can own tags too? It receives tag when item lies in it, when all items with that tag are gone from cell, cell loses this tag.
Is it possible to do “vaguer” queries at distance, and only do specific queries up close?
In other words, might it be possible to have a two-level query structure?
– Coarse level: what’s the closest cell that contains any food at all? If the closest cell is multiple cells away, then just start pathing towards the (centroid of the) cell.
– Fine level: now that you’re in or adjacent to the cell-with-food, exactly which bit of food do you want?
This kind of “aggregation at a distance” pattern seems like it would help a lot with ignoring the fact that there are 500 pieces of food in a given cell, for the (large majority of) actors that are far from that cell. The coarse query could be weighted by number of tagged items, so people would generally walk to the largest stockpile near them (as opposed to having ten people fight over one crust of bread that just happens to be slightly closer to them, while ignoring the massive stockpile a few cells over).
I would use a blooming filtering-like algorithm and run the calc for cells and containers. Any time food is added to a container (or cell, or area, or stack or whatever) you trip a “contains food” bit for the cell. Wheever a piece of food is removed you do a check for whether it is the last bit of food in that container and if so you flip the bit back to false. You then have a routine that stores the location of the closest container with the flag tripped. You then only need to flip bits on item movement and instead of 75,000 distance calls you only need a number of bit checks equal to the number of citizens. It is more storage overhead for your items/cells/containers, but it would save an enormous amount of CPU.
Sorry for the typos in my previous, but it was late and I was not anticipating a coding problem. At 256×256 you could easily store bitmaps of the entire world grid for each tag type. the “raw_food” bitmap would be 16KB like all the others. Every time an individual block had the first “raw_food” placed in it you would flip the corresponding bit in the “raw_food” bitmap to 1. When the last bit of food was removed from the block you flip it to 0. When a person needs to do a food check you create a 17×17 subset of the main “raw_food” bitmap centered on their location with a radius of 8. Take that AND a bitmap with an 8 radius circle of 1s around you OR a blank bitmap 17×17 and if it is the blank 17×17 you know there is “raw_food” within 8 blocks. If there is, then cut the radius in half and use 9x9s. If not double the radius and use 33x33s. With this halving and doubling you should very rarely if ever need more than 4 such operations. Once you have narrowed it down to a particular radius you then only need find *any* “raw_food” that matches that distance.
That should be : When a person needs to do a food check you create a 17×17 subset of the main “raw_food” bitmap centered on their location with a radius of 8. Take that AND a bitmap with an 8 radius circle of 1s around you and if it is the blank 17×17 you know there is *not* any “raw_food” within 8 blocks.
If you need a pathing algorithm rather than just a cartesian distance you can project the unavailable paths in the local area onto the circle of 1s to remove them from consideration at that distance.
This method will of course require more overhead per individual check, but the number of checks will now scale linearly with # of people rather than exponentially as a factor of people * food.
I remember the Rimworld developer have something similar used in his game.
But he further divided the zone into smaller one when wall is constructed, you might find his solution in one of his youtube devlog.
Could it be effective to structure things the way they are for us? That is, a colonist ‘remembers’ where some cooked food and/or raw food they’ve seen are, goes to find them, and eats them?
Why make them eat the closest of all possible food? Let them live! Pick 3 or so food items at random and have them eat the closest.